7 Basic NLP Models to Empower Your ML Application
Cheatsheet for BERT, XLNet, RoBERTa, ALBERT, StructBERT, T5, and ELECTRA.
Published
•3 min read
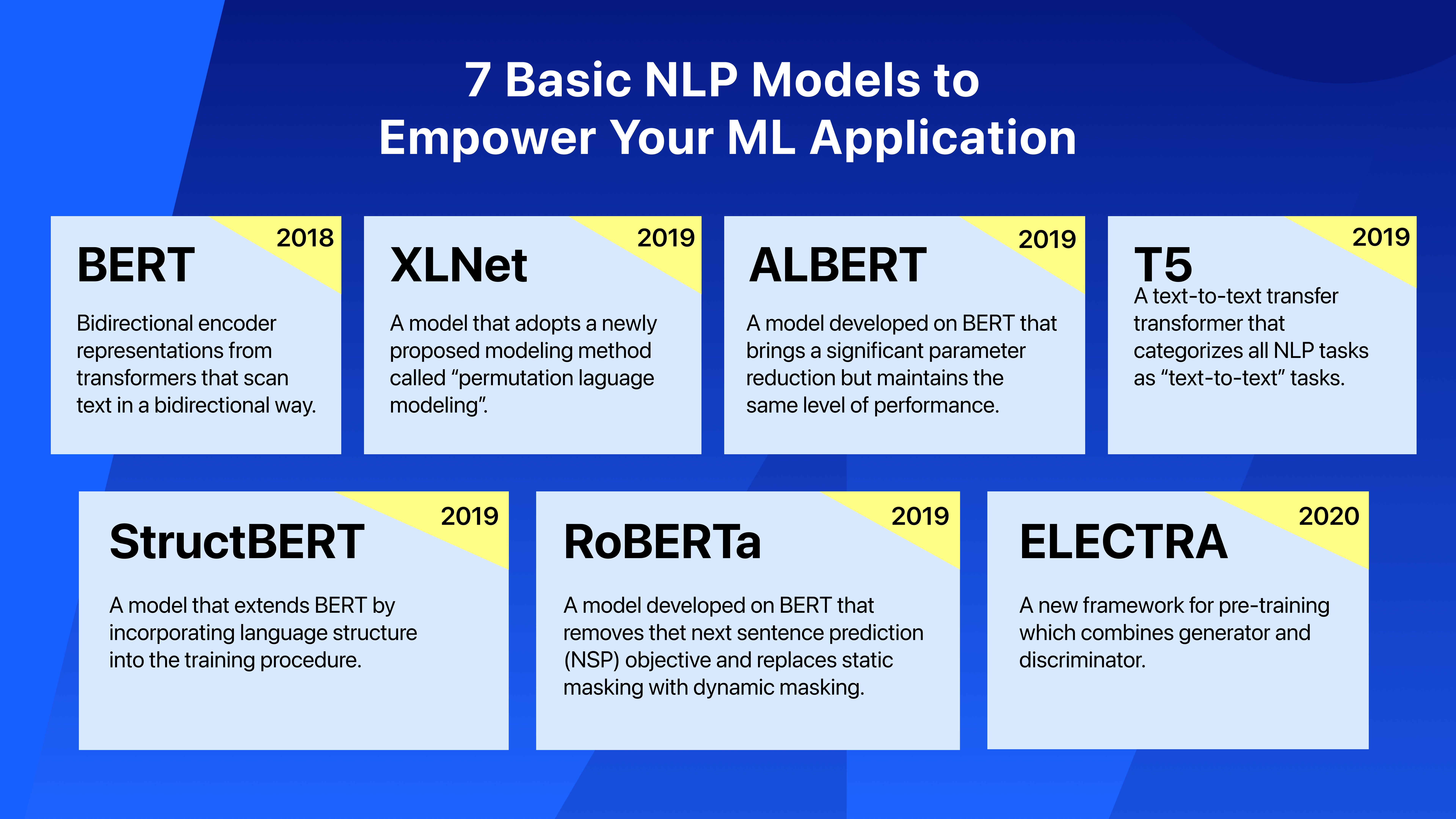
An overview of the 7 NLP models.
In the previous post, we have explained what is NLP and its real-world applications. In this post, we will continue to introduce some of the main deep-learning models used in NLP applications.
BERT
- Bidirectional Encoder Representations from Transformers (BERT) was first proposed in 2018 by Jacob Devlin in his paper "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding".
- The main breakthrough of the BERT model is that it scans text in a bidirectional way rather than a left-to-right or combined left-to-right and right-to-left sequence when looking at texts during training.
- There are two general types of BERT: BERT (base) and BERT (large). The difference is in configurable parameters: base-110 million parameter, large-345 million.
XLNet
- XLNet was published in the paper "XLNet: Generalized Autoregressive Pretraining for Language Understanding" in 2019.
- XLNet outperforms BERT by large margins in 20 benchmark tests as it leverages the best of both autoregressive models and bidirectional context modeling. XLNet adopts a newly proposed modeling method called "permutation language modeling".
- Unlike traditional tokenization in a language model that predict the word in a sentence based on the context of the previous token, XLNet's permutation language modeling takes into account the interdependency between tokens.
- XLNet achieves a performance test result of 2-15% improvement over BERT.
RoBERTa
- RoBERTa was proposed in the paper "RoBERTa: A Robustly Optimized BERT Pretraining Approach" in 2019.
- RoBERTa makes changes to the architecture and training procedures of BERT. Specifically, RoBERTa removes the next sentence prediction (NSP) objective, uses a much larger dataset than BERT, and replaces static masking with dynamic masking.
- RoBERTa achieves a performance test result of 2-20% improvement over BERT.
ALBERT
- ALBERT model was proposed in the paper "ALBERT: A Lite BERT for Self-supervised Learning of Language Representations" in 2019.
- ALBERT is developed based on the BERT model. Its major breakthrough is that it brings a significant parameter reduction but maintains the same level of performance compared to BERT.
- In ALBERT, parameters are shared across 12 layers of transformer encoders, while in the original BERT, each layer of encoders have a unique set of parameters.
StructBERT
- StructBERT was proposed in the paper "StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding" in 2019.
- StructBERT further extends BERT by incorporating language structure into the training procedure.
- StructBERT also introduces the word structural objective (WSO), which helps the model to learn the ordering of words.
T5
- T5 was introduced in the paper "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer" in 2019. T5 is the short form for "Text-to-Text Transfer Transformer".
- A clean, massive, and open-source dataset C4(Colossal Clean Crawled Corpus) is released in T5.
- T5 categorizes all NLP tasks as "text-to-text" tasks.
- There are five different sizes of T5 model, each with different number of parameters: T5-small (60 million parameters), T5-base (220 million parameters), T5-large (770 million parameters), T5-3B (3 billion parameters), T5-11B (11 billion parameters).
ELECTRA
- ELECTRA was proposed in the paper "ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators" in 2020.
- ELECTRA proposes a new framework for pre-training which combines generator and discriminator.
- ELECTRA changes the training method of masked language model to replaced token detection.
- ELECTRA performs better on small-sized models.



